

こんにちは、もちきなこです。今退職して転職活動をしながら、このブログを書いているのですが、私自身、前職がプログラマーだったのですが、あまり実務でコードを書いたことがなく、実務型研修のみの知識の段階で止まっていて、転職活動の面接時に復習が必要だなと思うことがあったため、今回新人研修時に一番好きだったDataBase部分について復習していきたいと思います。(一旦大まかに復習したい部分のみ書いているため、残りの部分に関しては後日更新します。)
データベースとは
データベースとは、ある規則に沿って作られた複数のテーブルの集まりです。例えば、下記のように、ある学校に所属している人についてのデータベースがあるとします。
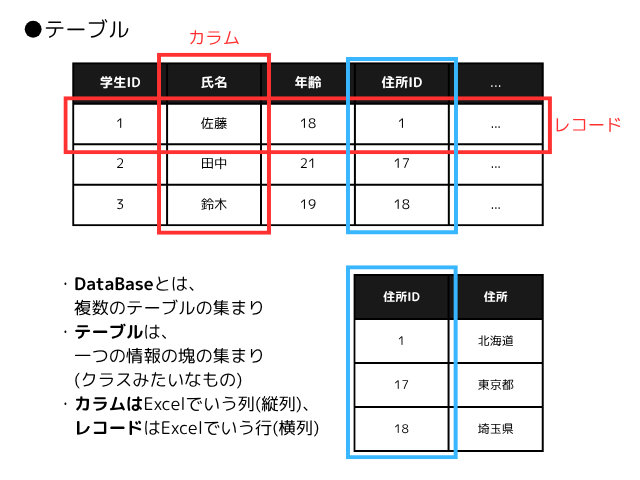
上記例では、「学生テーブル(上)」と「住所テーブル(下)」しかありませんが、考えられるテーブルの内容としては、他にも複数あり、例を出すと「教員テーブル」、「部活テーブル」、「教科テーブル」などが挙げられます。各テーブルのレコードは1つの情報の塊であり、人の場合は、それぞれが所属しているグループが複数あったりするので、その所属している団体の種類でもテーブルが作られます。
そして、もし別のグループの種類が固定で決まっているもの(今回でいう住所(都道府県)のように個数が固定なもの)に関しては、管理がしやすいように別でテーブルが作られ、IDで登録内容が紐づけされて、1つのテーブルを呼び出す際に、芋ずる式に詳細内容が取り出せるように整理されています。
SQL基礎
DDL(Data Definition Language: データ定義言語)は下記種類があります。
- CREATE
- DROP
- ALTER
「CREATE」はデータベースやテーブルの作成を行い、「DROP」はその削除、「ALTER」はその定義構成の変更を行います。
基本的には、データベースの環境構築時に使用し、テスト作業実行時などにもよく使われます。
DML(Date Manipulation Language: データ操作言語)は、下記種類があります。
- SELECT
- INSERT
- UPDATE
- DELETE
「SELECT」はレコードの検索抽出、「INSERT」は新規レコードの挿入、「UPDATE」は既存レコードの更新、「DELETE」は既存レコードの削除を行います。
基本的にはこの部分が、多くの人が使用する言語の部分で、データに変更を行う「INSERT文, UPDATE文, DELETE文」の3つに関しては、扱いを慎重にしなければいけません。テーブル同士の整合性が崩れないように、作業をする順番や、途中で処理が止まった場合の処理など、想定しておくべきことが多いです。
DCL(Data Control Language: データ制御言語)は、下記種類があります。
- COMMIT
- ROLLBACK
- GRANT
- REVOKE
「COMMIT」はデータベースに対して実行された変更を確定します。最初にデータベースを行う時のよくある失敗で、変更をした後に、この「COMMIT文」を実行せずに終了してしまい、変更が水の泡になってしまったなどがあります。必ず変更をしたらこの「COMMIT文」を実行し、変更を確定しましょう。
「ROLLBACK」はデータベースに対して実行された変更を取り消し、元の状態に戻します。「ROLLBACK文」は、データベースの処理途中で想定外のエラーなどが起きた場合に、処理を中断し、途中まで変更された内容を破棄し、変更前の状態に戻します。
わかりやすい例でいうと、お金の問題の方がイメージしやすいかもしれません。銀行口座から指定された金額のお金を移動する際に、「①お金を指定口座から引き出す」「②指定された口座に振り込む」「③正常に終了したら処理内容をデータとして登録する」という手順があったとします。この場合、もし②の段階でエラーが起きてしまった場合に、①の処理が実行されてしまっているためこのまま処理を確定(COMMIT)してしまうと、お金が引き出されている(減っている)のに、入金がされていない状態になり、お金の処理の整合性がなくなってしまいます。そのため、処理の途中でエラーが出てしまった場合に、全ての処理をもとの状態に戻し(ROLLBACK)、データの整合性を保ちます。「COMMIT文」があるのも、正常な状態でのみ変更内容を確定し、データの整合性を保つためです。
「GRANT」はユーザに操作権限を与え、「REVOKE」はユーザから操作権限を奪います。この2つは管理者の権限を変更するうえで必要な命令文で、基本的には管理者の交代であったり、環境構築の部分でしか使用しないイメージが強いです。
演算子
比較演算子は、①左辺と右辺が等しいことを表す「=」、②左辺と右辺が等しくないことを表す「<>」、③右辺以上左辺を表す「>=」、④右辺より大きい左辺を表す「>」、⑤右辺以下左辺を表す「<=」、⑥右辺より小さいを表す「<」があります。いろいろな言語が混ざって②を忘れがちなので注意です。また、データベースでは値が入っていない場合、NULLという値が使用されます。NULLに関して判定をしたい場合、①NULLである「IS NULL」、②NULLではない「IS NOT NULL」が使用されます(判定する値は左辺にしか置けない)。データベースを使用したシステムによっては、データベースで取得したNULLの値をスペースに置き換えたり、そもそもNULLの値を許さず、値がない場合にはスペースを入力するなどしてデータの登録時に条件を付けて処理を行っていたりもします。
論理演算子は、①両辺の条件が成り立つことが条件が成立することを表す「AND演算子」、②片方の条件が成り立てば条件が成立することを表す「OR演算子」、③条件の否定を表す「NOT演算子」があります。論理演算子ではありませんが「OR演算子」の強化版に「IN」があります「IN」はOR条件が複数ある場合に簡易的に記載できます。また、論理演算子を複数記載する場合(複合条件)に、「()括弧」で優先順位を明らかにしたりしますが、より内容が複雑な場合は、後述するサブクエリというものを利用します。
集約関数
集約関数は基本的に「関数名(列名)」などで表される、なじみ深いものでいうとExcelなどでも良くつかわれている関数の、合計値(SUM)や平均値(AVG)などが挙げられます。これらは、複数のレコードをまとめて(集約して)、結果を出すため、集約関数と呼ばれます。基本的に全体検索だと「*」を括弧内に記載して検索しますが、指定列の値が入っていない項目(NULL項目)を除外したい場合、括弧内に指定列名を記載します。
集約関数の中でも、グループ化を行う「GROUP BY句」は、集約範囲を全体ではなく、複数の部分に分けて行います。全体を複数グループに分けるということです。また、集約キーにNULLが含まれる場合、NULLはNULLとしてまとめられてグループ分けされます。NULLを集約要素に入れたくない場合には、「WHERE句(絞り込み条件句)」でNULL項目を除外し、[GROUP BY句」を使用します。そして、この「GROUP BY句」が書ける場所は、「SELECT句」と「HAVING句(グループの各要素に対する絞り込み条件句)」、「ORDER BY句」のみです。それぞれの要素については後述します。また、「WHERE句」では、集約関数は使えません。
「HAVING句」は、グループの各要素に対する絞り込みの条件句です。WHERE句との違いは、絞り込みの範囲で、「WHERE句」はデータ全体に対しての行の絞り込み、「HAVING句」は、グループ分けされたものに対して絞り込みを行います。
そのため、SELECT文の実行順序としては、下記になります。
FROM句→WHERE句→GROUP BY句→HAVING句→SELECT句
FROM句で対象のテーブルを指定します(その指定されたテーブルから抽出)。その後、WHERE句で全体に対して行での絞り込みを行い、GROUP BY句で複数のグループに分け、HAVING句で分けられたグループの各要素に対して絞り込みを行い、SELECT句で今回表示する項目(列)範囲を指定するという流れです。
ソート(並べ替え)
ソートは、「ORDER BY句」を使用します。降順がDESC、昇順がASCで記載し、同じ列項目に対する複数のソート条件を同時に記載することもできます。複数ソート条件を記載した場合には、左側に記載条件から順に実行され、そのソート結果に対して右側の条件が順に実行されていきます。
SELECT文全体の実行順序としては下記になります。
FROM句→WHERE句→GROUP BY句→HAVING句→SELECT句→ORDER BY句
表示したい部分を抽出し終わってからソートを行います。
結合
複数のテーブルにまたがってデータを操作する場合、テーブルの結合を行います。テーブルにはそれぞれ主キーと呼ばれるキーが1つ以上あり、それによってデータの整合性が保たれています。キーが複数ある場合に関しては難易度が高いので省略します(うろ覚えで理解が薄いため)が、複合キーというものを使用しているテーブルも存在します。
結合には大きく分けて2種類あり、内部結合と外部結合があります。
内部結合は、結合キーが結合に使われるテーブルの両方にある場合でないとレコードとして表示されません。外部結合は、結合キーがどちらかになくても結合元のテーブルにレコードがあれば表示され、該当するレコードがなければNULLとして表示されます。左外部結合、右外部結合という種類がありますが、結合する基準になっている結合元のテーブルがどちらなのかを表しているだけの違いです。正規化前のテーブルの状態に戻す。と考えるとわかりやすいと思います。結合の時に気を付けなければならないのは、それぞれのテーブルごとの別名の部分で、どのテーブルからどのカラムの値を持ってくるのかを正確に明記しなければエラーが発生します。
結合ではありませんが、テーブルの共通部分を抜き出す「INTERSECT演算子」やテーブルの共通部分を除く「MINUS演算子」などもあります。
サブクエリ(副問い合わせ)
サブクエリとは、SELCET文の中にある入れ子構造のSELECT文です。集約関数のところで、「WHERE句には集約関数が使えない」と書きましたが、ただ集約関数を書くのではなく、サブクエリとして先に集約関数のSELECT文を実行し、その値を主のSELECT文で用いることができます。注意点として、WHERE句にサブクエリを記載する場合には、サブクエリの値が単一(スカラ・サブクエリ)になるようにしないとエラーが発生します。
サブクエリだけではありませんが、主SELCET文のテーブルとの関係性と、今実際に何のテーブルのどのカラムを扱っていて、最終的にどのようなデータを抽出したいのかが明確になっていないとエラーが発生しやすいです。この部分は混乱しやすいので、私も要復習項目です。
復習①感想
ざっと簡単に基礎部分を見直しましたが、うろ覚えの部分が多かったため、自分で理解を深める方法として今回ブログを書いてよかったと思います。業務でデータベースを使用するとなると、この基礎部分がおろそかになっているとエラーを大量に生成しそうなので、エラーが出ても落ち着いて条件を整理し、取得したいデータを抽出できるように、今度は、今回まとめたことも復習しながら実際にデータベースを動かしていきたいと思いました。
研修中には、サブクエリだったりいろいろ触っていたのですtが、実務では完成されているSQL文を設計書で見る機会しかなかったので、整理されているデータをいじりながら自分の思い描いたデータを抽出する面白さを思い出しました。
すぐに構文が出てこなくても、記載の仕方や考えの整理の仕方がわかっていれば、構文は検索で出てくるはずなので、一つ一つ基礎を積み重ねて成長していきたいと思います。


コメント